AI SEO Tool That Works With Every LLM: A Developer's Guide in 2026
Mitu Das
super admin

If you searched "AI SEO tool," you're probably looking for one of three things: a plain-language definition, a comparison of the current options, or a way to actually build AI into your own SEO workflow instead of paying for another dashboard. This guide covers all three - starting with the definition, moving through a real comparison of what's on the market in 2026, then walking through a code-level tool (@power-seo/ai) I use myself, line by line, with every code sample taken directly from its own documentation.
What Is an AI SEO Tool
An AI SEO tool is software that uses a large language model (or a rules engine trained on SEO patterns) to automate tasks that used to require a human strategist: writing meta descriptions and title tags, finding content gaps, predicting which SERP features a page can win, and - increasingly - tracking whether a brand gets cited inside AI-generated answers on ChatGPT, Gemini, or Perplexity rather than just ranked in ten blue links.
In practice, "AI SEO tool" now covers two very different kinds of product, and mixing them up is the most common mistake I see people make when evaluating options:
- Full SaaS platforms you log into - Semrush One, Surfer SEO, Search Atlas - which crawl your site, run their own models, and give you a dashboard.
- Code-level libraries you import into your own app - like
@power-seo/ai- which give you the prompting and parsing logic but let you bring your own LLM and keep the output inside your own pipeline.
Which one you need depends on whether you want a tool to use, or a capability to build on top of. The rest of this guide covers both, starting with the landscape.
AI SEO Tool Landscape: A Straight Comparison
I tested or cross-referenced each of these against its own documentation and independent reviews rather than relying on marketing copy alone.
| Tool | Category | What it actually does | Best fit |
|---|---|---|---|
| Semrush One | Full SaaS suite | Merges Semrush's classic 55+ tool SEO suite with an AI Visibility Toolkit that tracks brand mentions across ChatGPT, Gemini, Perplexity, and Google AI Overviews from one dashboard | Teams that want SEO and AI-visibility tracking in a single subscription |
| Surfer SEO | Content optimization | The Surfer SEO content editor scores drafts against top-ranking pages for structure, entities, and keyword usage while you write | Writers and editors who want a narrow, deep content-scoring tool rather than a full suite |
| Search Atlas (Otto SEO) | Autonomous execution | Otto SEO doesn't just recommend fixes - it deploys them directly (title tags, schema, internal links) through a site-installed pixel or Cloudflare DNS connection | Agencies that want AI to execute changes, not just suggest them |
@power-seo/ai | Code library | Provider-agnostic prompt builders and parsers you call from your own app, plus a deterministic (no-LLM) SERP eligibility checker | Developers who want SEO logic inside their own CMS, CI pipeline, or Next.js app |
This isn't an exhaustive "best AI SEO tools" ranking - pricing and feature sets change fast enough that any specific numbers I quoted today could be stale by the time you read this, so I've focused on what each tool structurally does rather than what it costs.
AI Search Visibility Is Its Own Category Now
Across all of the platforms above, tracking whether you're cited inside an AI-generated answer - sometimes called AI visibility or GEO (generative engine optimization) - has become a distinct discipline from classic rank tracking. Getting cited in a ChatGPT answer, a Perplexity result, or a Google AI Mode overview depends on different signals than ranking in ten blue links: clear structure, citable facts, complete schema markup, and content freshness matter more than backlink volume alone. That's the practical core of the "AI SEO vs. traditional SEO" debate - the two disciplines overlap heavily (solid semantic HTML and structured data help with both), but the measurement layer genuinely differs, which is why current tool comparisons increasingly score AI-citation tracking separately from search-rank tracking.
How to Choose: Matching the Tool to the Intent Behind Your Search
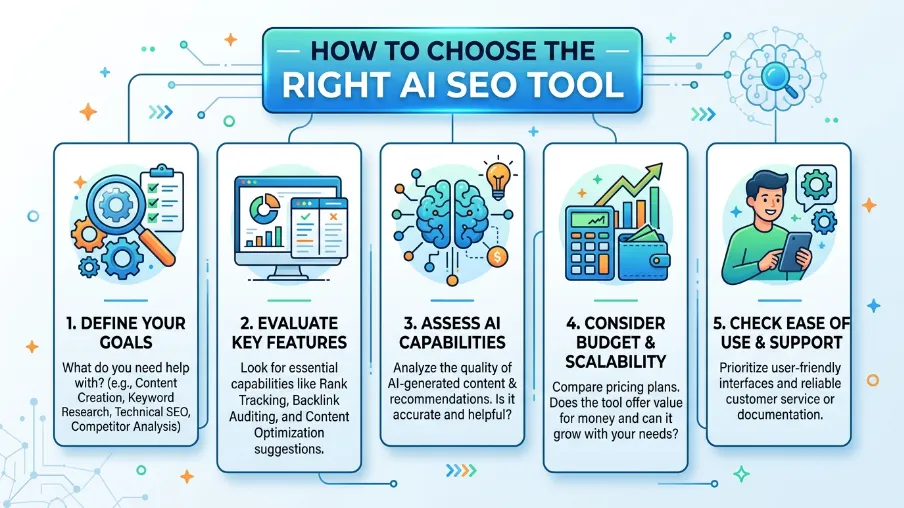
If you're evaluating options rather than reading for background, here's the decision framework I actually use:
You want a dashboard and don't want to write code → a full suite like Semrush One (broad) or Surfer SEO (narrow, content-focused) is the right call. - You want AI to make live changes to your site without developer involvement → Search Atlas's Otto SEO is built specifically for that. - You want SEO logic embedded inside your own CMS, build pipeline, or CI checks, using whichever LLM you already pay for → that's the gap a code library like @power-seo/ai fills, and it's the one I'll walk through for the rest of this guide, because it's the option most existing SEO comparisons skip entirely.
Hands-On: Building AI SEO Directly Into a Next.js App
This is the part based on direct experience rather than research - I use this pattern in production, and every snippet below is copied unmodified from the package's own documentation so you can verify it yourself.
The Problem With Most AI SEO Tooling at the Code Level
Every LLM provider - OpenAI, Anthropic Claude, Google Gemini, Mistral, local Ollama - has its own SDK, its own authentication pattern, and its own API shape. If you build an SEO content pipeline around GPT-4o today and want to switch to Claude tomorrow, you end up rewriting your prompting logic every time, even though the actual SEO task (write a meta description, find content gaps) hasn't changed. @power-seo/ai extracts that SEO-specific prompting and parsing logic into reusable, provider-agnostic building blocks, then gets out of your way.
What It Actually Is
Prompt builders return a plain { system, user, maxTokens } object. You pass that object to whatever LLM client you already have. There's no bundled SDK, no API keys managed, and no network calls made by the package itself - which matters for trust and auditability if you're deploying this inside a client's stack.
- Meta description generation -
buildMetaDescriptionPrompttargets 120–158 character descriptions with the focus keyphrase and a call-to-action;parseMetaDescriptionResponseextracts a candidate with validation status, character count, and estimated pixel width. - SEO title generation -buildTitlePromptproduces prompts for 5 optimized title tag variants;parseTitleResponsereturns typed candidates with character counts. - Content improvement suggestions -buildContentSuggestionsPromptanalyzes existing content for gaps and returns typed suggestions for headings, paragraphs, keywords, and links, each with a priority level. - SERP feature prediction -buildSerpPredictionPromptandparseSerpPredictionResponsepredict which SERP features a page is likely to earn, with likelihood scores and requirement breakdowns. - Rule-based SERP eligibility -analyzeSerpEligibilityis fully deterministic. No LLM, no cost, instant execution. It inspects schema markup and content structure for FAQ, HowTo, Product, and Article rich-result eligibility.
Installing It
npm install @power-seo/ai
# or
yarn add @power-seo/ai
# or
pnpm add @power-seo/ai
Zero runtime dependencies. The package is pure TypeScript, tree-shakable, ships both ESM and CJS formats, and is safe for SSR, Edge runtimes (Cloudflare Workers, Vercel Edge, Deno), and Node.js environments.
Meta Descriptions in Under 20 Lines
import { buildMetaDescriptionPrompt, parseMetaDescriptionResponse } from '@power-seo/ai';
// 1. Build the prompt
const prompt = buildMetaDescriptionPrompt({
title: 'Best Coffee Shops in New York City',
content: 'Explore the top 15 coffee shops in NYC, from specialty espresso bars in Brooklyn...',
focusKeyphrase: 'coffee shops nyc',
});
// 2. Send to your LLM of choice (example uses OpenAI)
import OpenAI from 'openai';
const openai = new OpenAI({ apiKey: process.env.OPENAI_API_KEY });
const response = await openai.chat.completions.create({
model: 'gpt-4o',
messages: [
{ role: 'system', content: prompt.system },
{ role: 'user', content: prompt.user },
],
max_tokens: prompt.maxTokens,
});
// 3. Parse the raw text response
const result = parseMetaDescriptionResponse(response.choices[0].message.content ?? '');
console.log(`"${result.description}" - ${result.charCount} chars, ~${result.pixelWidth}px`);
console.log(`Valid: ${result.isValid}`);
The buildMetaDescriptionPrompt call returns a plain object - { system, user, maxTokens }. You decide what to do with it. The OpenAI client is something you already have. @power-seo/ai never touches your API keys.
Provider Flexibility: Why This Matters for Trust and Longevity
You can swap providers on the same prompt object with zero friction, which also means you're never locked into one vendor's pricing or roadmap:
// OpenAI
import OpenAI from 'openai';
import { buildMetaDescriptionPrompt, parseMetaDescriptionResponse } from '@power-seo/ai';
const openai = new OpenAI({ apiKey: process.env.OPENAI_API_KEY });
const prompt = buildMetaDescriptionPrompt({
title: 'My Article',
content: '...',
focusKeyphrase: 'my topic',
});
const openaiResponse = await openai.chat.completions.create({
model: 'gpt-4o',
messages: [
{ role: 'system', content: prompt.system },
{ role: 'user', content: prompt.user },
],
max_tokens: prompt.maxTokens,
});
const result = parseMetaDescriptionResponse(openaiResponse.choices[0].message.content ?? '');
// Anthropic Claude
import Anthropic from '@anthropic-ai/sdk';
const anthropic = new Anthropic({ apiKey: process.env.ANTHROPIC_API_KEY });
const claudeResponse = await anthropic.messages.create({
model: 'claude-opus-4-6',
system: prompt.system,
messages: [{ role: 'user', content: prompt.user }],
max_tokens: prompt.maxTokens,
});
const result2 = parseMetaDescriptionResponse(
claudeResponse.content[0].type === 'text' ? claudeResponse.content[0].text : '',
);
// Google Gemini
import { GoogleGenerativeAI } from '@google/generative-ai';
const genai = new GoogleGenerativeAI(process.env.GEMINI_API_KEY!);
const model = genai.getGenerativeModel({ model: 'gemini-1.5-pro' });
const geminiResponse = await model.generateContent(`${prompt.system}\n\n${prompt.user}`);
const result3 = parseMetaDescriptionResponse(geminiResponse.response.text());
The prompt object is identical across all three calls. Only the transport changes - which means you can run a genuine multi-LLM A/B test, comparing OpenAI, Claude, and Gemini output quality on identical prompts, and measure the actual click-through impact in Search Console instead of taking any single vendor's word for which model writes better copy.
SEO Title Generation: Five Variants, Type-Safe
import { buildTitlePrompt, parseTitleResponse } from '@power-seo/ai';
import type { TitleInput, TitleResult } from '@power-seo/ai';
const input: TitleInput = {
content: 'Article about the best tools for keyword research in 2026...',
focusKeyphrase: 'keyword research tools',
tone: 'informative',
};
const prompt = buildTitlePrompt(input);
const rawResponse = await yourLLM.complete(prompt.system, prompt.user, prompt.maxTokens);
const results: TitleResult[] = parseTitleResponse(rawResponse);
results.forEach(({ title, charCount, pixelWidth }, i) => {
const status = charCount <= 60 ? 'OK' : 'TOO LONG';
console.log(`${i + 1}. "${title}" - ${charCount} chars [${status}]`);
});
pixelWidth matters because Google truncates results based on rendered pixel width, not character count - a detail that's easy to get wrong if you're only checking character limits.
Content Improvement Suggestions
import { buildContentSuggestionsPrompt, parseContentSuggestionsResponse } from '@power-seo/ai';
import type { ContentSuggestionInput, ContentSuggestion } from '@power-seo/ai';
const input: ContentSuggestionInput = {
title: 'React SEO Best Practices',
content: '<h1>React SEO</h1><p>React is a JavaScript library...</p>',
focusKeyphrase: 'react seo best practices',
analysisResults: 'Current score: 58/100. Missing headings structure.',
};
const prompt = buildContentSuggestionsPrompt(input);
const rawResponse = await yourLLM.complete(prompt.system, prompt.user, prompt.maxTokens);
const suggestions: ContentSuggestion[] = parseContentSuggestionsResponse(rawResponse);
suggestions.forEach(({ type, suggestion, priority }) => {
console.log(`[Priority ${priority}] ${type}: ${suggestion}`);
});
This is the piece I'd wire into a headless CMS pipeline - functionally the same job Surfer SEO's content editor or Search Atlas's Content Genius does inside their own dashboards, just as a function you own and can audit.
SERP Feature Prediction: LLM-Powered and Deterministic Variants
import { buildSerpPredictionPrompt, parseSerpPredictionResponse } from '@power-seo/ai';
import type { SerpFeatureInput, SerpFeaturePrediction } from '@power-seo/ai';
const input: SerpFeatureInput = {
title: 'How to Make Cold Brew Coffee at Home',
content: '<h1>Cold Brew Coffee</h1><h2>Step 1: Grind the Coffee</h2><p>...</p>',
schema: ['HowTo', 'Recipe'],
contentType: 'guide',
};
const prompt = buildSerpPredictionPrompt(input);
const rawResponse = await yourLLM.complete(prompt.system, prompt.user, prompt.maxTokens);
const predictions: SerpFeaturePrediction[] = parseSerpPredictionResponse(rawResponse);
predictions.forEach(({ feature, likelihood, requirements, met }) => {
console.log(`${feature}: ${(likelihood * 100).toFixed(0)}% likelihood`);
console.log(` Requirements: ${requirements.join(', ')}`);
console.log(` Met: ${met.join(', ')}`);
});
The deterministic version, analyzeSerpEligibility, needs no LLM, no API call, and no cost - and it's the function I trust the most precisely because it's not probabilistic:
import { analyzeSerpEligibility } from '@power-seo/ai';
// HowTo - detected by step-structured headings and HowTo schema
const result = analyzeSerpEligibility({
title: 'How to Install Node.js on Ubuntu',
content: '<h2>Step 1: Update apt</h2><p>...</p><h2>Step 2: Install nvm</h2><p>...</p>',
schema: ['HowTo'],
});
// Returns array with SerpFeaturePrediction objects, including:
// { feature: 'how-to', likelihood: 0.8, requirements: [...], met: [...] }
// FAQ - detected by FAQPage schema
const faqResult = analyzeSerpEligibility({
title: 'React SEO FAQ',
content: '<h2>Does React hurt SEO?</h2><p>...</p><h2>How do I add meta tags?</h2><p>...</p>',
schema: ['FAQPage'],
});
I run this exact function in CI to catch schema regressions - a HowTo page that silently loses its step structure, or a FAQ page that loses its FAQPage markup - before Google stops showing the rich result, not after.
Full Type System
import type {
PromptTemplate, // { system: string; user: string; maxTokens?: number }
MetaDescriptionInput, // { title, content, focusKeyphrase?, maxLength?, tone? }
MetaDescriptionResult, // { description, charCount, pixelWidth, isValid, validationMessage? }
ContentSuggestionInput, // { title, content, focusKeyphrase?, analysisResults? }
ContentSuggestionType, // 'heading' | 'paragraph' | 'keyword' | 'link'
ContentSuggestion, // { type: ContentSuggestionType; suggestion: string; priority: number }
SerpFeature, // 'featured-snippet' | 'faq-rich-result' | 'how-to' | 'product' | 'review' | 'video' | 'image-pack' | 'local-pack' | 'sitelinks'
SerpFeatureInput, // { title, content, schema?, contentType? }
SerpFeaturePrediction, // { feature: SerpFeature; likelihood: number; requirements: string[]; met: string[] }
TitleInput, // { content, focusKeyphrase?, tone? }
TitleResult, // { title: string; charCount: number; pixelWidth: number }
} from '@power-seo/ai';
Real-World Use Cases
- Headless CMS publish-time suggestions - on "Publish," fire a server action calling
buildMetaDescriptionPromptandbuildTitlePrompt, then show authors candidates before the page goes live. - Programmatic SEO pipelines - generate unique, keyphrase-targeted meta copy across thousands of location, product, or category pages at build time or in server components. - Content quality dashboards - pairbuildContentSuggestionsPromptwith a scoring package to surface prioritized remediation actions. - CI rich-result regression testing - addanalyzeSerpEligibilityto your test suite so schema regressions are caught before Google stops showing your rich results. - Multi-LLM benchmarking - run identical prompt builders against OpenAI, Claude, and Gemini, logcharCountandpixelWidth, and measure click-through rate per model.
Does an AI SEO Tool Like This Integrate With Vercel or Cloudflare
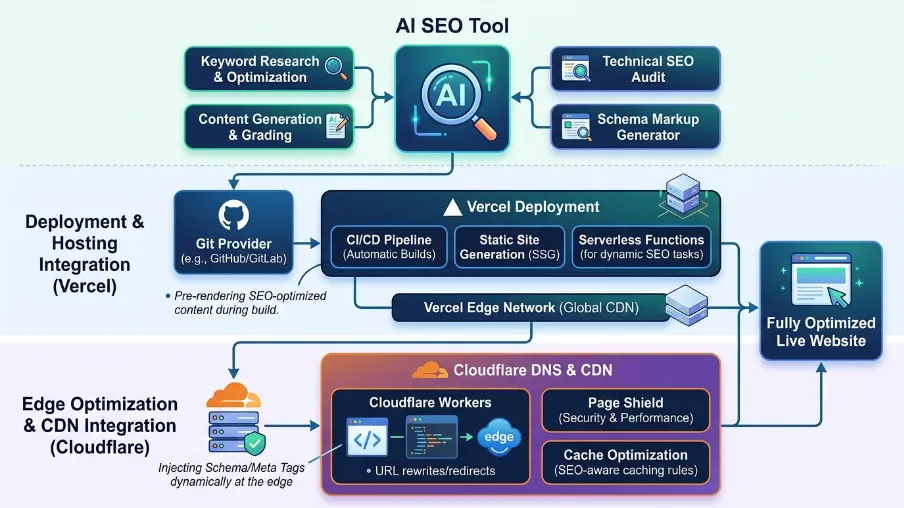
The answer depends on which category of tool you mean, and it's worth being precise rather than vague here:
- Full SaaS suites (Semrush One, Surfer SEO, Search Atlas/Otto) work at the website level, not the framework level. They analyze your live URLs or, in Otto's case, sit in front of them via an installed pixel or DNS-level connection - Search Atlas specifically supports activating Otto through Cloudflare DNS as a faster alternative to manual pixel installation. None of them plug into your Vercel build pipeline or Cloudflare Workers code directly; they work against whatever is already deployed, regardless of host. - Code libraries like
@power-seo/aiare the category that actually runs inside Vercel and Cloudflare, because they have zero Node.js-specific dependencies. You can call the prompt builders and parsers from a Vercel Edge Function, a Next.js server action, or a Cloudflare Worker directly.
So: if the question is "which dashboard integrates with my host," none of the SaaS tools need to, since they work at the domain level. If the question is "which package can I import and run inside my Vercel or Cloudflare deployment," that's the code-library category - a much shorter list.
My Honest Take
The most effective AI SEO tool isn't necessarily the one with the fanciest dashboard - it's the one that fits inside the workflow you already have. A full suite like Semrush One or Search Atlas makes sense when you want a tool to operate; @power-seo/ai makes sense when you want a capability to build on. I use both categories for different reasons, and I'd be skeptical of any comparison that tells you one replaces the other outright - they solve different problems.
The deterministic analyzeSerpEligibility function is the piece I'd single out as underrated: running it in CI catches schema regressions at the code level, which is a gap most dashboard-only tools don't cover.
Frequently Asked Questions About AI SEO Tool
What is an AI SEO tool, in one sentence?
Software that uses a language model or a rules engine to automate SEO tasks - writing meta descriptions and titles, finding content gaps, predicting SERP features, or tracking AI-search citations - that previously required manual work.
Are AI SEO tools replacing traditional SEO?
No - they overlap. Traditional SEO signals (semantic HTML, structured data, backlinks, page experience) still matter for both classic rankings and AI-answer citations. What's changed is that AI-search visibility now needs its own tracking layer alongside rank tracking, because the two aren't measured the same way.
How do I install @power-seo/ai?
Run npm install @power-seo/ai, yarn add @power-seo/ai, or pnpm add @power-seo/ai. Zero runtime dependencies.
Is @power-seo/ai safe to use in Next.js App Router, Edge runtimes, and Cloudflare Workers?
Yes. It's pure TypeScript with no browser-specific or Node.js-specific APIs, so it's safe for SSR, Cloudflare Workers, Vercel Edge Functions, Deno, and standard Node.js.
Is the package tree-shakeable and TypeScript-first?
Yes on both counts - it ships with "sideEffects": false and named exports per function, and is written in pure TypeScript with comprehensive type definitions.
Does the package make any network calls or manage API keys?
No. It makes zero network calls and manages no API keys. All LLM communication happens through your own client code; the package only builds prompt strings and parses raw text responses.


FAQ
Frequently Asked Questions
We offer end-to-end digital solutions including website design & development, UI/UX design, SEO, custom ERP systems, graphics & brand identity, and digital marketing.
Timelines vary by project scope. A standard website typically takes 3-6 weeks, while complex ERP or web application projects may take 2-5 months.
Yes - we offer ongoing support and maintenance packages for all projects. Our team is available to handle updates, bug fixes, performance monitoring, and feature additions.
Absolutely. Visit our Works section to browse our portfolio of completed projects across various industries and service categories.
Simply reach out via our contact form or call us directly. We will schedule a free consultation to understand your needs and provide a tailored proposal.